Qu’est-ce que le langage ? Qu’est-ce qu’un code ?
Les deux termes sont utilisés dans le langage courant pour désigner un peu tout et son contraire. En voici quelques exemples tirés de la presse quotidienne.
- On parle souvent de « langage codé ou de « codes de langage »
« Les hôtels des ventes ont leur langage codé. » Ouest-France, Jean-François VALLÉE, 09/12/2012 ;
« Ils se parlent par langage codé, qui ne peut se comprendre qu’entre eux. » Le divan familial, 2006, Christiane Joubert, Richard Durastante (Cairn.info) ;
« Les nouveaux codes de langage des marques (storytelling web radio, TV…), la qualité de l’expression, des contenus et des langages font la différence. » Les nouveaux codes de langage – media.electre-ng.com.
- Il peut aussi être question de « codes sociaux », de « codes du comportement », de « codes culturels » ou de « codes vestimentaires »
« Le code social est un système de langage, de comportements et de signaux corporels (gestes, postures, vêtements, coiffure, accessoires…) qui transmettent ce message : « J’appartiens (ou je n’appartiens pas ». TSA | Association Ikigaï ;
« Faire ses achats demande des ajustements et implique la découverte de nouveaux codes culturels. » Comprendre les codes culturels – CQRHT ;
« Un code vestimentaire constitue un ensemble de règles tacites ou explicites régissant la manière dont les individus doivent se vêtir en fonction du contexte dans lequel ils évoluent. Ces codes sont façonnés par des normes culturelles, des traditions et des attentes. »
- De la même façon, on parle de « code gestuel », de « codes secrets », de « code informatique »
« Dans cet article, un ergonome présente le ‘code gestuel’ constitué de règles d’action qui permet d’observer les manutentionnaires en action et de les aider à trouver la meilleure posture de travail. » portaildocumentaire.inrs.fr, docLe code gestuel : mieux comprendre et prévenir les risques en entreprise.
La confusion est particulièrement flagrante dans le domaine de l’informatique. Regardez par exemple cet extrait d’un site dédié à l’apprentissage de la programmation [1] :
« La différence principale entre le langage de script et le langage de programmation est que le code source écrit dans un langage de script est converti en code machine à l’aide d’un interpréteur, tandis que le code source écrit dans un langage de programmation est converti en code machine à l’aide d’un compilateur ou d’un interprète. »
Vous avez compris quelque chose ? Moi non plus. J’ai parcouru plusieurs sites de ce type qui proposent d’expliquer ces termes, mais ils utilisent tous les termes « code », « langage », « langage de codage », « codage du langage », etc. de façon incompréhensible pour un non-initié. Toujours est-il que cela a peu de choses avoir avec le langage humain, sinon que dans les deux cas, il y a des « signes » (ici des suites de 0 et de 1/là des mots), qui correspondent à des « sens » (ici des instructions au programme informatique/là des concepts) et qu’ils ont une « syntaxe », c’est-à-dire une organisation formelle de ces signes.
Comme on peut le voir, les termes « code », « langage » et « communication » semblent être plus ou moins interchangeables dans l’usage courant. Comment définir plus clairement ces concepts ?
Quelques définitions
Au départ, un « code » est « Un recueil de lois, de textes ayant force de loi. » (Le Grand Robert), comme le Code de Justinien ou d’Hammourabi, le Code Noir réglant l’esclavage en Louisiane au 17ième siècle.
Par extension, un code peut être un ensemble de règlements, explicites comme dans le Code de la Route, ou implicites comme dans le code de la morale, du goût, de l’honneur, etc.
Ensuite, on appelle par ce terme « Un système ou recueil de conventions constituant un ensemble de signes » (Code Morse, code télégraphique, etc.) Et par extension, dans un emploi plus technique : « Tout système rigoureux de correspondance entre ensembles de signes ou d’arrangements d’unités qui permettent la transmission d’information. » (Code informatique, code génétique, etc. mais aussi Code vestimentaire, code social, etc.)
Si on veut être un petit peu rigoureux, on dirait que, par définition, un code est constitué d’un ensemble de signes fixes, en nombre limité, auxquels correspond un ensemble d’éléments de « sens », également fixes et en nombre limité. Autrement dit, en termes mathématiques, un code est une bijection : tout élément de l’ensemble « signes » correspond à un et un seul élément de l’ensemble « sens » et inversement.
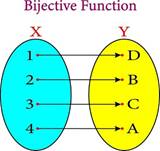
Signes -> Sens
C’est en cela qu’ils diffèrent du langage, composé d’un nombre illimité de « signes », les mots, dont les combinaisons possibles sont infinies, et dont le sens peut évoluer avec le temps.
Que penser alors de l’usage courant ?
En fait, la notion de « code » semble avoir évolué, dans l’esprit du public, vers l’idée de « tout ensemble de signes », c’est-à-dire, tout ensemble d’éléments qui correspondent à l’existence ou à la vérité d’une chose. Par exemple, le ‘code vestimentaire’ voudrait dire un ensemble d’éléments vestimentaires qui « signifieraient » qu’on est riche ou pauvre, ouvrier manuel ou employé de bureau, à la mode ou démodé, etc., évidemment selon des critères totalement subjectifs et parfois connus seulement de quelques personnes. En ce sens, le « code du langage » signifierait que certains éléments de langage auraient un double sens, un premier sens ordinaire, connu de tout un chacun, et un second sens caché, connu des seuls initiés. De même pour le « langage diplomatique » ou « le langage scientifique ».
La plupart des codes correspondent à la définition donnée plus haut. Il y a des codes gestuels, comme le langage des signes, des codes tactiles, comme le Braille, des codes visuels, comme le sémaphore ou les panneaux de signalisation routières, des codes sonores, comme le Morse, ou des codes écrits.
Le concept de code va nous servir pour nous aider à distinguer du langage humain par exemple les différents systèmes de communication des animaux. On retiendra pour l’instant les principes qu’on vient d’énoncer : les codes sont des ensembles fixes de signes et de sens dans une relation biunivoque : ni le sens, ni le signe ne peut varier ou être ambigu ; pour chaque signe il y a un et seulement un sens et pour chaque sens il y a un et seulement un signe.
Le langage humain est donc très différent d’un code, car les « signes », c’est-à-dire des mots, mais pas seulement, peuvent varier dans le temps, être compris différemment par différents locuteurs dans différents contextes, avoir plusieurs sens pour un même locuteur, disparaître, passer d’une langue à une autre, souvent en changeant de sens, etc.
Quelques exemples de codes : le Code Morse, l’alphabet

Le Code Morse est un bon exemple pour commencer car il est très simple à comprendre et facile à utiliser. Une série d’impulsions électriques, où alternent les « longs » et les « courts » permet de représenter les lettres de l’alphabet. Donc, avec ce code on peut facilement représenter n’importe quel mot de n’importe quelle langue utilisant cet alphabet.
Mais qu’en est-il de l’alphabet lui-même ? Est-ce un code comme les autres ? Oui et non. Oui parce que, en théorie, chaque lettre représente un son et que chaque son est représenté par une lettre. Mais dans la pratique, comme le savent bien ceux qui essaie d’apprendre l’orthographe d’une langue étrangère, les choses sont loin d’être aussi simples.
Si on prend pour exemple l’orthographe anglaise, l’une des plus compliqués qui soit, les 26 lettres de l’alphabet représentent 44 (ou 46 selon les spécialistes) sons différents, mais qui peuvent être orthographiés de 1120 façons différentes ! Par exemple, le son /ɛ/ qui correspond normalement à la lettre E, comme dans bed,peut en fait être transcrit par IE dans friend, par EA dans dead, par A dans any, par AI dans again, etc.
Pour ne considérer que l’orthographe française, relativement opaque par rapport à d’autres systèmes, comme l’espagnol ou l’italien, une même lettre peut aussi correspondre à différents sons, par exemple la lettre S : cassé, case, sac, garçons : deux S entre voyelles correspond au son /s/, alors qu’un seul correspond à /z/. Si ce ‘s’est en début de mot, on entend /s/ mais en fin de mot, on a /Ø/, c’est-à-dire rien, ou alors /s/ comme dans ‘fils’ (descendant masculin), contrairement à ‘fils’ deux tiges de métal qui ne prononce pas le S.
Les sons du français ont changé depuis l’ancien français, alors que les lettres restent les mêmes, ce qui donne lieu à quelques étrangetés, comme le S final muet, ou la voyelle surmontée d’une cédille, qui indique qu’il y avait un S après la voyelle autrefois. Il en est de même pour l’anglais, dont la prononciation a changé radicalement pendant la transition du vieil anglais à l’anglais moderne, mais dont l’orthographe est restée essentiellement la même.
Et, comme le même alphabet est utilisé pour toutes les langues de l’Europe de l’Ouest, on a parfois des sons très différents pour une même lettre. Sans parler des voyelles, dont le son peut varier considérablement, les consonnes S, CH, G, ou J correspondent à des sons différents selon la langue ou la position de la lettre dans la langue.
Les sons du français ont changé depuis l’ancien français, alors que les lettres restent les mêmes, ce qui donne lieu à quelques étrangetés, comme le S final muet, ou la voyelle surmontée d’une cédille, qui indique qu’il y avait un S après la voyelle autrefois. Il en est de même pour l’anglais, dont la prononciation a changé radicalement pendant la transition du vieil anglais à l’anglais moderne, mais dont l’orthographe est restée essentiellement la même.
Et, comme le même alphabet est utilisé pour toutes les langues de l’Europe de l’Ouest, on a parfois des sons très différents pour une même lettre. Sans parler des voyelles, dont le son peut varier considérablement, les consonnes S, CH, G, ou J correspondent à des sons différents selon la langue ou la position de la lettre dans la langue.
| LETTRE | SON FRANÇAIS | SON ANGLAIS | SON ALLEMAND |
| S | /s/ ou /z/ sait ou case | /s/ ou /z/ ‘seven’ ou ‘reason’ | /s/ ou /z/ ‘los’ ou ‘sagt’ |
| CH | /ʃ/ ‘chat’ | /tʃ/ ‘chat’ | /ç/ ou /x/ ‘nicht’ ou Nacht’ |
| J | /ȝ/ ‘jour’ | /dȝ/ ‘judge’ | /j/ ‘jah’ |
| G | /g/ ou /ȝ/ ‘garage’ | /g/ ou /ȝ/ ‘garage’ | /g/ ou /ȝ/ ou /k/ ‘garage’ ‘Tag’ |
Le Code de la Route
Si le Code Morse est véhiculé par le son, les panneaux du Code de la Route utilisent le canal visuel. En voici quelques exemples :
Danger : forme triangulaire, bord rouge, fond blanc, dessin noir

Interdiction : forme ronde, bord rouge, fond rouge et blanc, dessin noir

Interdiction assortie de conditions : forme ronde, bord rouge, fond rouge et bleu

Obligation : forme ronde, bord blanc, fond bleu, dessin blanc

L’œil doit saisir rapidement un ensemble d’informations visuelles et les décoder pour trouver le sens du panneau. On peut parler d’une forme de communication particulière : l’émetteur est le service de la voirie, le récepteur est l’automobiliste. Il y a un message dans un sens : le récepteur ne répond pas, il agit selon les indications données.
Il existe des dizaines de codes qui ont posé d’énormes problèmes de décryptage, dont l’un des plus célèbres est le code secret de Mary Stuart, Reine d’Ecosse.
Les codes secrets au cours de l’histoire [2]
Jules César a utilisé divers types de codes secrets. Dans La Guerre des Gaules [3], il raconte qu’il envoya un message à Cicéron dans lequel les lettres latines étaient remplacées par les lettres grecques correspondantes ; cela suffisait à rendre illisible le message par l’ennemi (pas assez cultivé pour connaître le grec !) mais limpide pour Cicéron. Dans La Vie des douze Césars, Suétone en décrit un autre méthode utilisée par César : on remplace chaque lettre du message par la lettre placée trois rangs après elle dans l’alphabet. [4] Dans les deux cas, il s’agit d’un codage « mono-alphabétique » ou « monographique ». Chaque lettre est remplacée par un symbole ; dans les deux exemples donnés il s’agissait d’une autre lettre de l’alphabet ou d’une lettre d’un autre alphabet, mais ce pourrait aussi être un symbole n’ayant aucune autre signification ou un dessin.
Un progrès décisif dans le déchiffrement des messages cryptés fut accompli dans la civilisation arabo-islamique ; les savants arabes se sont intéressés à la linguistique et découvrirent que certaines lettres sont plus utilisées que d’autres. Al Kindi rédigea au IXème siècle un Manuscrit sur le déchiffrement des messages cryptographiques où il utilise cette particularité. Cette méthode porte le nom d’analyse des fréquences. Transposons-la au français : les trois lettres les plus employées en français sont les lettres E, A et I ; en présence d’un texte crypté (dont on a de bonnes raisons de penser qu’il est écrit en français), on compte la fréquence d’apparition de chaque lettre dans le texte crypté. Les trois lettres les plus répandues sont probablement mises pour E, A et I (mais éventuellement dans un ordre différent). On repère également les couples fréquents avec ces trois lettres cryptées : par exemple, si on pense que la lettre H code la lettre E, on repérera dans le texte crypté les lettres qui suivent le plus fréquemment le H et on fera l’hypothèse qu’elles sont mises pour T ou N. Ensuite, on emploie une technique bien connue des amateurs de mots croisés consistant à deviner des mots dont on connaît seulement certaines lettres.
Cette technique permet de venir à bout de tout message crypté grâce à un système mono-alphabétique, à condition qu’il soit suffisamment long –une quarantaine de lettres- et composé de mots « normaux ». La méthode fonctionne également si on choisit de remplacer chaque lettre, non pas par une autre lettre, mais par un symbole sans signification particulière (par exemple un rond pour A, un carré pour B, etc.) ; il suffit d’appliquer la méthode des fréquences à ces symboles. Un exemple de ce type de déchiffrement est donné dans Les hommes dansants, une nouvelle d’Arthur Conan Doyle où l’on voit Sherlock Holmes déchiffrer des messages où chaque lettre est codée par un « bonhomme » dans une position différente.
Les méthodes d’encryptage se sont énormément complexifiées au cours de l’histoire et on arrêtera ici notre présentation, à l’exception d’un dernier exemple : le code secret de Marie Stuart, Reine d’Écosse.
Le code secret de Marie Stuart, Reine d’Écosse

Née le 8 décembre 1542, Mary Stuart a été condamnée et exécutée le 8 février 1587 pour avoir conspiré à assassiner la Reine d’Angleterre. Sa condamnation était basée sur la découverte de lettres secrètes échangées avec des officiels français qui contenaient des informations sensibles concernant ses intrigues pour récupérer le trône écossais et usurper le pouvoir de sa cousine germaine et rivale politique, Élisabeth 1ère. Ces lettres étaient écrites avec un code secret qui a défié les cryptographes du monde entier pendant des siècles. Mais récemment, une équipe composée de trois cryptographes amateurs, George Lasry, informaticien français vivant en Israël, Norbert Biermann, professeur allemand d’opéra, et Satoshi Tomokiyo, physicien japonais, a trouvé la solution.
À l’aide d’une combinaison complexe de logiciels informatiques et de techniques de cryptographie traditionnelles, ces trois hommes ont réussi à casser les cryptogrammes de Marie Stuart, révélant ainsi un trésor d’informations inédites sur le monarque et son environnement politique.
La première tâche du trio a été de transcrire les 150 000 signes contenus dans les messages codés en symboles qu’un ordinateur actuel puisse reconnaître ; un processus qui a pris plusieurs mois. Comme ces caractères comprenaient 191 symboles différents, l’équipe savait que les messages codés n’étaient pas simplement chiffrés par substitution, système dans lequel chaque lettre de l’alphabet est assignée à un signe correspondant. À la place, ils ont émis l’hypothèse que ces messages secrets avaient été composés à l’aide d’un code homophonique, système plus complexe dans lequel une lettre de l’alphabet peut être assignée à plusieurs symboles différents, ce qui rend le code plus bien plus difficile à déchiffrer.
La difficulté était accrue par le fait que le trio ne savait pas dans quelle langue étaient écrites les 50 lettres dont ils disposées. Après avoir essayé l’italien, le latin et l’espagnol, ils se sont souvenus que Mary avait passé son enfance en France et ils ont essayé le français. Bingo ! Ils ont fait mouliner le logiciel et sont tombés sur quelques mots qui revenaient régulièrement, notamment fils et ma liberté. Chaque fois qu’ils trouvaient un mot compréhensible, ils en faisaient un mot clé et continuaient leurs recherches. Mais plusieurs mois de travail ne révélaient rien d’intéressant. Alors ils ont compris que, contrairement à beaucoup de codes de ce type, les symboles du code ne correspondaient pas toujours à des lettres de l’alphabet, mais pouvaient aussi renvoyer à des mots, voire à des suites de mots. Voici quelques correspondances entre les signes du code et des lettres ou des mots anglais.

Née le 8 décembre 1542, Mary Stuart a été condamnée et exécutée le 8 février 1587 pour avoir conspiré à assassiner la Reine d’Angleterre. Sa condamnation était basée sur la découverte de lettres secrètes échangées avec des officiels français qui contenaient des informations sensibles concernant ses intrigues pour récupérer le trône écossais et usurper le pouvoir de sa cousine germaine et rivale politique, Élisabeth 1ère. Ces lettres étaient écrites avec un code secret qui a défié les cryptographes du monde entier pendant des siècles. Récemment, une équipe composée de trois cryptographes amateurs, George Lasry, informaticien français vivant en Israël, Norbert Biermann, professeur allemand d’opéra, et Satoshi Tomokiyo, physicien japonais, a trouvé la solution.
À l’aide d’une combinaison complexe de logiciels informatiques et de techniques de cryptographie traditionnelles, ces trois hommes ont réussi à casser les cryptogrammes de Marie Stuart, révélant ainsi un trésor d’informations inédites sur le monarque et son environnement politique.
La première tâche du trio a été de transcrire les 150 000 signes contenus dans les messages codés en symboles qu’un ordinateur actuel puisse reconnaître ; un processus qui a pris plusieurs mois. Comme ces caractères comprenaient 191 symboles différents, l’équipe savait que les messages codés n’étaient pas simplement chiffrés par substitution, système dans lequel chaque lettre de l’alphabet est assignée à un signe correspondant. À la place, ils ont émis l’hypothèse que ces messages secrets avaient été composés à l’aide d’un code homophonique, système plus complexe dans lequel une lettre de l’alphabet peut être assignée à plusieurs symboles différents, ce qui rend le code plus bien plus difficile à déchiffrer.
La difficulté était accrue par le fait que le trio ne savait pas dans quelle langue étaient écrites les quelques 50 lettres dont ils disposaient. Après avoir essayé l’italien, le latin et l’espagnol, ils se sont souvenus que Mary avait passé son enfance en France et ils ont essayé le français. Bingo ! Ils ont fait mouliner le logiciel et sont tombés sur quelques mots qui revenaient régulièrement, notamment fils et ma liberté. Chaque fois qu’ils trouvaient un mot compréhensible, ils en faisaient un mot clé et continuaient leurs recherches. Mais plusieurs mois de travail ne révélaient rien d’intéressant. Alors ils ont compris que, contrairement à beaucoup de codes de ce type, les symboles du code ne correspondaient pas toujours à des lettres de l’alphabet, mais pouvaient aussi renvoyer à des mots, voire à des suites de mots. Voici les correspondances entre les signes du code et des lettres ou des mots anglais.

Selon l’article sur le site de la National Geographic [5] :
« Plusieurs lettres montrent en détail l’astucieuse habileté de Marie en matière de subterfuge politique, qu’il s’agisse de ses tentatives de soudoyer les conseillers d’Élisabeth ou bien de l’orchestration d’un mariage entre cette dernière et le duc d’Anjou, qui était le beau-frère de Marie. On y trouve également consignées ses tentatives de récupération du trône écossais et son implication dans le Complot de Throckmorton de 1583 visant à renverser Élisabeth. »
Il y a d’autres cas fascinants de codes secrets qui ont posé d’énormes problèmes aux cryptographes, comme la machine Enigma, conçue par les Allemands pendant la seconde guerre mondiale. [6]
Conclusion
Le langage humain est incroyablement plus complexe que tous ce que nous avons considéré jusqu’ici. Les mots du langage sont polyvalents, c’est-à-dire qu’ils ont plusieurs sens possibles selon les contextes. Ces sens peuvent changer avec le temps. Ils peuvent signifier des objets concrets ou des concepts abstraits, désigner des événements passés ou imaginaires, avoir des connotations, c’est-à-dire des notions secondaires associés par implication au sens premier. Et on pourrait continuer comme ça pendant des pages et des pages.
On poursuivra notre enquête sur le langage dans les prochains articles. La prochaine fois on parlera de la communication par et entre les plantes.
Références
[1] https://fr.differkinome.com/articles/technology/what-is-the-difference-between-scripting-language-and-programming-language.html
[2] Cette section doit beaucoup à l’article de Martine Bühler : « Arithmétique et codes secrets : Un coup d’œil historique », https://bibnum.publimath.fr/IPS/IPS02026.pdf.
{3] Cesar De bello Gallico (La Guerre des Gaules) Traduction L.A. Constans Les Belles Lettres 1937.
[4] Suetone De Vita Caesarum (La Vie des Douze Cesars) Traduction Henri Ailloud Les Belles Lettres 1961.
[5] « Ces lettres codées ont été décryptées… révélant un complot contre la reine Élisabeth Ière », https://www.nationalgeographic.fr/histoire/marie-stuart-histoire-angleterre-ces-lettres-codees-ont-ete-decryptees-revelant-un-complot-contre-la-reine-elisabeth-ire.
[6] Voir par exemple : https://fr.wikipedia.org/wiki/Enigma_(machine).

Laisser un commentaire